Andrej Karpathy published a gist a while back about how LLMs process and retrieve information. The core idea is simple: an LLM's output quality is bounded by the quality of its context. Structure your context well and the model performs. Feed it a mess and you get a mess back, just faster.
That idea has been rattling around my head for months, because it describes a problem I was living with every day.
The problem with twelve files
Orient is our first client. A 79-year-old B2B industrial printing manufacturer. We built them 18 Claude projects spanning seven departments: sales proposals, digital marketing, vendor procurement, financial operations, ERP development, recruitment, and servicing.
Each of those projects has its own set of instruction files, guides, and skills. And each of those files needs to know things about Orient. The correct company name. The brand colour ratio. The tone for a collections email versus a cold outreach versus an internal HR memo. The exact tagline. The exact font.
For a while, we handled this the obvious way: copy the relevant facts into each project's instruction files. The company name went into twelve documents. The brand system went into eight. The voice rules went into fourteen.
Then Orient corrected their company name. It wasn't “TPH Orient Group.” It was “The Printers House Orient.” One correction. Twelve files to update. And the worst part: I only found eleven of them. The twelfth kept generating documents with the wrong name for two weeks before anyone noticed.
That's when I stopped thinking of client knowledge as a pile of text files and started thinking of it as a data problem.
One fact, one home
The fix was a wiki. Not a Notion wiki or a Confluence space. A purpose-built markdown wiki with a strict rule: every fact about a client lives in exactly one file, and every other file that needs that fact points to the source rather than restating it.
The company name lives in identity.md. The colour system lives in brand-system.md. Voice rules live in tone-and-voice.md. If you want to know something about Orient, there's one file to check.
This is database thinking applied to LLM context. Normalisation. Single source of truth. Foreign keys instead of duplicated rows. The same principles that make a relational database reliable make an LLM knowledge base reliable, for exactly the same reasons.
Three layers
The wiki has three layers, and the direction of data flow between them matters.
Layer 1: Sources. The messy real world. Brand guidelines in a PDF, pricing in a spreadsheet, corrections from a WhatsApp message, product specs from an internal doc. These get ingested into the wiki but are never served directly to a Claude project.
Layer 2: The wiki. The canonical truth. Six fact pages for Orient: identity, brand system, tone and voice, products and machines, channels and integrations, and a project catalog. Every fact has one home. Every page has schema-versioned frontmatter: title, status, owner, last updated, source references, tags.
Layer 3: Downstream files. The instruction files, guides, and skills that are actually loaded into Claude projects. These are generated from the wiki through a distillation process. They are not hand-written. When a wiki fact changes, the downstream files get regenerated to match.
The flow is always one-directional. Sources feed the wiki. The wiki feeds downstream. Downstream never writes back to the wiki, and the wiki never serves raw source material. This is what keeps the system clean.
The prime directive
The wiki's convention file opens with a rule that governs every operation:
Do not infer. Do not summarise creatively. Quote source spans verbatim.
This is the difference between a wiki and a chatbot. The wiki doesn't interpret. It records. When a source says the company tagline is “From Offset to Inkjet, books to labels and everything packaging,” the wiki stores that exact string. Downstream files can paraphrase for their audience, but the wiki preserves ground truth.
I can't overstate how much this matters. The moment you let an LLM paraphrase facts at the storage layer, you've introduced drift at the source. Every downstream file inherits that drift, and now you're back to playing whack-a-mole with twelve documents that all say slightly different things.
Drift detection
The most valuable feature in the system is automated drift detection. Every project page in the wiki declares which fact pages it depends on. Orient's sales comms project, for example, depends on:
tone-and-voice.mdfor voice rules and email signaturesbrand-system.mdfor presentation styling and Poppins typographyidentity.mdfor the company name and heritagechannels.mdfor Apollo and M365 contractsproducts-and-machines.mdfor machine names
When identity.mdgets updated — say, the company name correction from “TPH Orient Group” to “The Printers House Orient” — a single command scans every project that depends on identity and flags which downstream files now contain stale claims.
No manual memory required. The system tells you exactly what's out of date and why. That company name correction that took me two weeks to fully propagate by hand? The wiki catches it in seconds.
Five commands, strict boundaries
Five purpose-built slash commands operate on the wiki:
/ingest routes new source material into the wiki. A brand guideline PDF, a pricing correction from the client, a product spec from their internal docs. It writes to a staging directory, never directly to live pages.
/distill regenerates a downstream file from wiki facts. When the wiki changes, this is how the change reaches the instruction files that Claude actually reads. Again, staging only.
/distill-check is read-only. It compares a downstream file against the current wiki state and reports any drift. This is the command I run most often.
/recapsynthesises a focused brief from wiki pages on a specific topic. Useful when you need to quickly pull together everything the wiki knows about, say, Orient's digital printing lineup without reading six files. Output goes to stdout, nothing is written.
/lintis a weekly health check. It scans for contradictions between pages, stale content that hasn't been reviewed, orphaned pages that nothing depends on, and missing cross-references.
The critical design decision: mutating commands only write to staging. Nothing goes live without human review. The wiki enforces a “propose, review, apply” workflow. I could have automated the full loop, but the cost of a wrong fact propagating to 18 projects is high enough that the review step earns its keep.
The knowledge graph
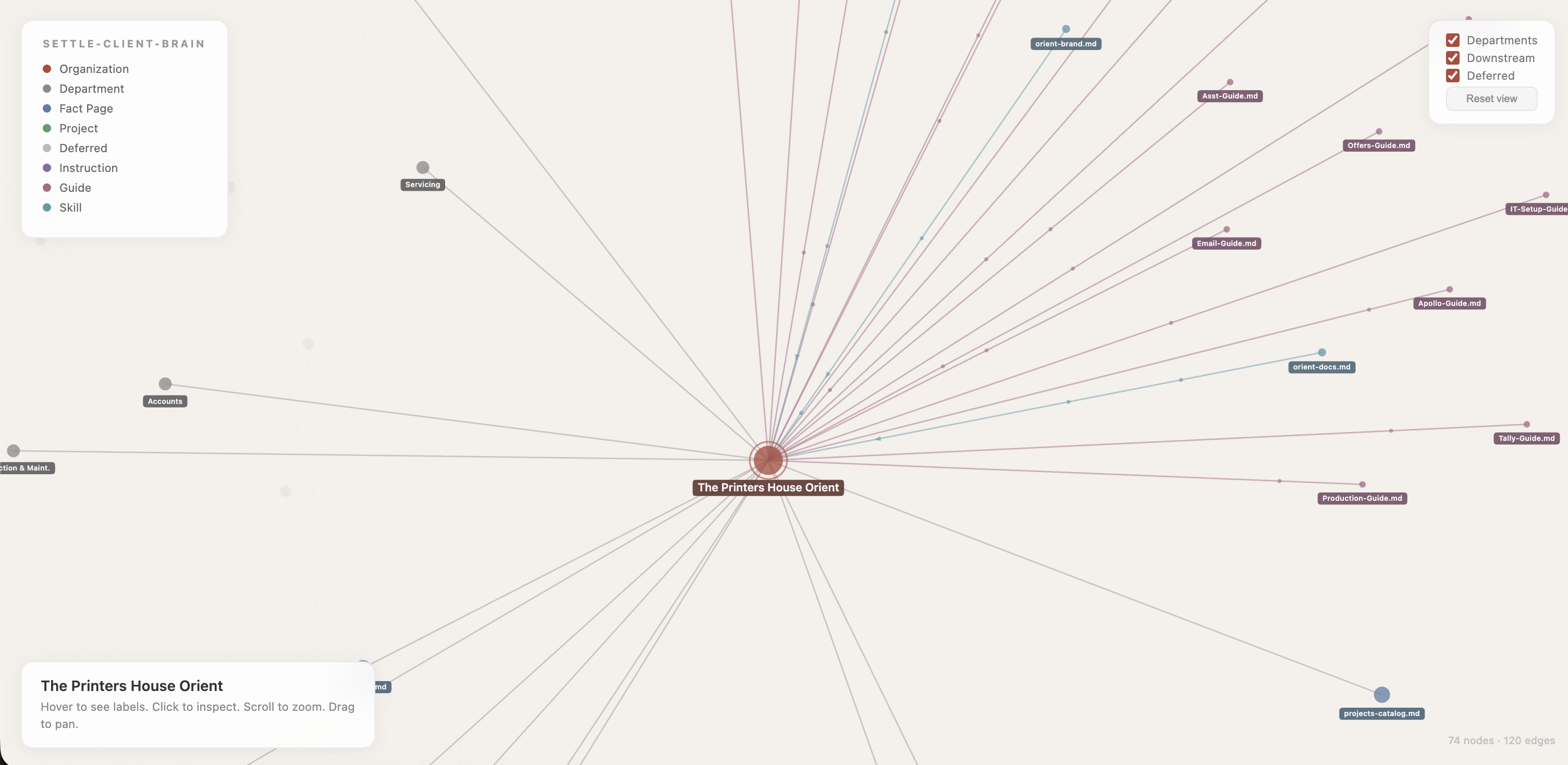
To visualise how all these pieces connect, I built an interactive knowledge graph. It renders the entire system in the browser: the organisation at the centre, departments radiating outward, fact pages forming a ring of canonical truth, projects orbiting further out, and downstream instruction, guide, and skill files at the edges.
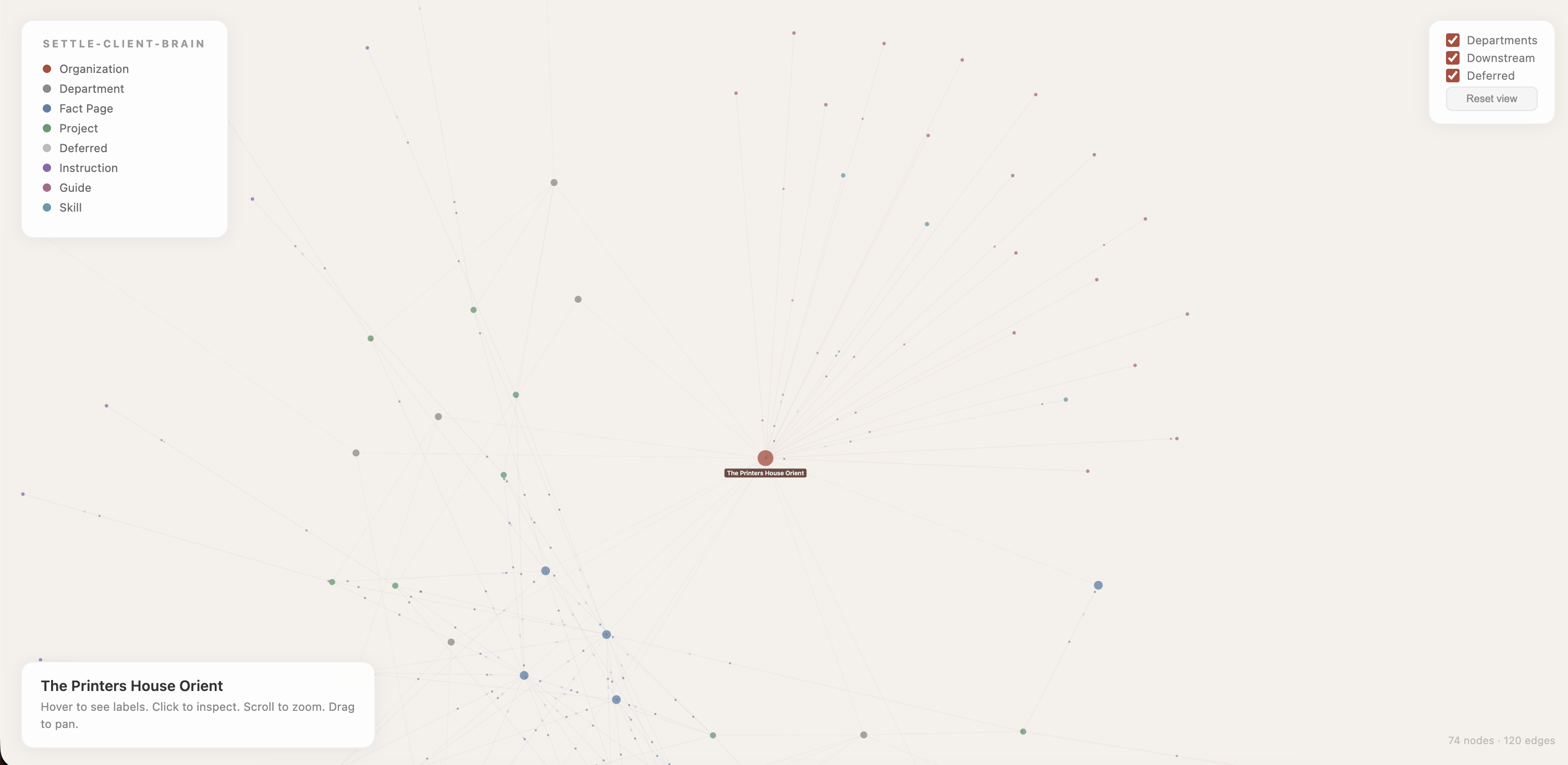
Animated particles flow along the edges showing the direction of data: facts flow from the wiki into projects, projects distill into instruction files. Hover over any node and the graph lights up only its direct connections. Everything else fades.
This is the part that changed how I think about the problem. When you can see the graph, you can see the blast radius. Click on identity.md and you immediately see every project, every instruction file, every guide that would need to update if a fact in that page changed. The graph turns an abstract dependency problem into something spatial and obvious.
Multi-tenant from day one
The wiki is namespaced by client organisation. Orient is the first tenant. Their namespace contains six fact pages, 18 project pages, and a sync tracker: a three-layer status board showing which projects are in sync with the wiki, which have been distilled, and which have been deployed to live Claude instances.
When a second client onboards, they get their own namespace with the same structure. The shared infrastructure — schema, conventions, slash commands, templates — stays at the root. The per-client data is isolated. This is the same pattern you'd use in any multi-tenant SaaS, applied to a knowledge management system.
Orient's numbers: 74 nodes, 120 edges, six fact pages feeding 18 projects feeding dozens of downstream instruction files. For a company with seven departments and a decade of accumulated product knowledge, those numbers will grow. The wiki is built to handle that growth without the kind of inconsistency that made me build it in the first place.
The append-only log
Every change to the wiki gets a one-line entry in log.md: timestamp, actor, affected paths, and a summary. Seeds, ingestions, distillations, drift findings. The log is append-only. Nothing gets edited or deleted from it.
This matters more than it sounds like it should. When a client asks “why does my proposal generator use this phrasing?” I can trace the answer backward: the instruction file was distilled from tone-and-voice.md on a specific date, which was last updated from a source PDF the client sent on another specific date. The full provenance chain is there in the log.
It also catches a subtle class of problems. If someone runs /ingeston the same source document twice by mistake, the log shows it. If a distillation didn't propagate a change, the log shows that too. An audit trail isn't glamorous, but when you're managing knowledge for someone else's business, accountability is the foundation everything else rests on.
Why this matters
For a company like Orient with 18 Claude projects spanning seven departments, the cost of inconsistency is enormous. One project saying the company is “TPH Orient Group” while another says “The Printers House Orient” erodes trust. One project using Montserrat while the brand system mandates Poppins creates visual dissonance. These aren't hypothetical examples. Both happened before the wiki existed.
The wiki eliminates this class of error entirely. Not by being careful, but by making it structurally impossible. Facts have one home. Downstream files are generated, not hand-written. Drift is detected automatically. The system doesn't rely on human memory. It enforces consistency through architecture.
That's what Karpathy's insight looks like when you apply it to a consulting practice. Treat client knowledge as a first-class data system — not as a pile of text files — and the quality of everything downstream improves automatically. The bottleneck was never the model. It was the instructions.
74 nodes. 120 edges. One source of truth. Start a conversation →